Heute setze ich mich in einer Kundensituation mit einem nicht-funktionalen Failover-Verhaltens eines Entrust Identity Essentials Cluster auseinander. Bei einem Ausfalltest des primären Servers wurde festgestellt, dass der sekundäre Server nicht korrekt übernimmt und somit keine OTP-Codes versendet. Folglich ist das damit abgesicherte Remote Access VPN (RAVPN) im Notfall nicht nutzbar.
Umgebung
Die Infrastruktur besteht aus zwei autarken FortiGate-Clustern, einem Cisco ISE-Cluster mit zwei Nodes sowie einem Entrust Identity Essentials-Cluster aus zwei Servern. Alle Systeme sind auf zwei getrennte Rechenzentren verteilt. Die folgende Darstellung ist stark vereinfacht und bezieht sich darauf, welches System jeweils den primären Zugriffsweg darstellt. Die Cisco ISE Nodes und die Entrust-Server sind zwar geclustert, aber haben eigene IP-Adressen und lassen sich eigenständig ansprechen. Über Prioritäten beziehungsweise Sequenzreihenfolgen werden die Primär- und Sekundärsysteme festgelegt.
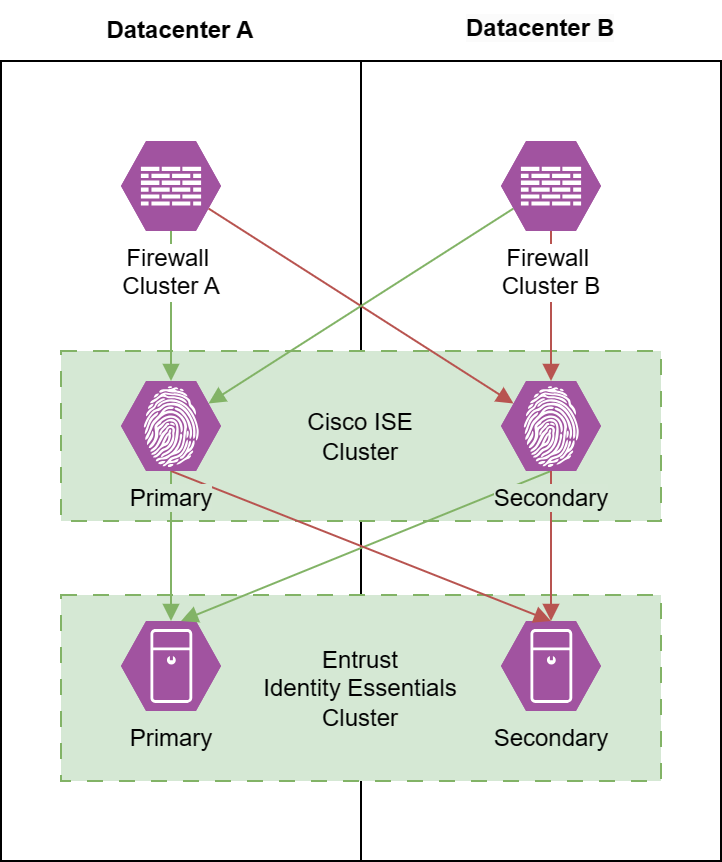
Bei einer Anmeldung für das RAVPN sendet das jeweilige FortiGate Cluster einen RADIUS-Access-Request zur primären Cisco ISE. Diese leiten es ihrerseits die Anfrage weiter an die Entrust-Server, welche dann nach korrekter AD-Authentifizierung den Code versendet.
Analyse und Anpassung
Im Troubleshooting-Prozess wird nun geprüft, ob zunächst die Firewall-Regeln zwischen allen Systemen korrekt aufgebaut sind und die Kommunikationswege jeweils zugelassen sind. Dies gilt auch für die Cluster-interne Kommunikation, da hier die Cluster in jeweils Standort-spezifischen Subnetzen stehen und das Forwarding über die Firewalls erfolgt. Hier kann kein Fehler festgestellt werden.
Da die Anmeldungen, egal ob an das VPN-Gateway im Datacenter A und Datacenter B an der primären Cisco ISE ankommen und protokolliert werden, können die beiden Firewall-Cluster aus der Fehlerbetrachtung ausgeschlossen werden. Ebenfalls werden die Cisco ISE unter den RADIUS-Servers als erreichbar gemeldet.
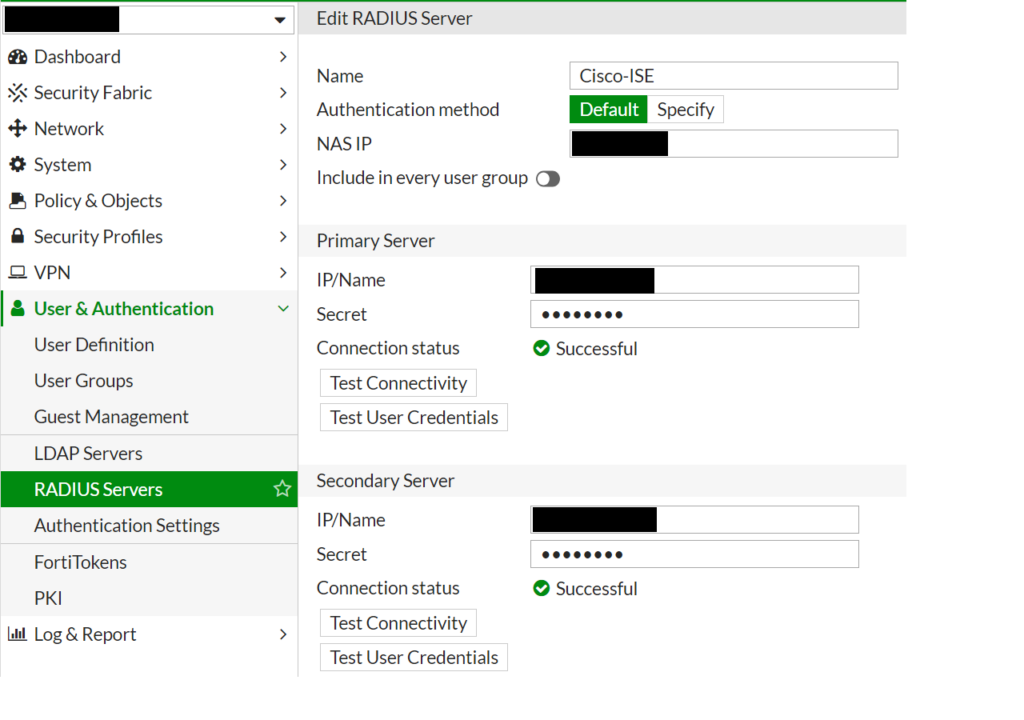
Wir ändern unseren Fokus nun daher auf die Cisco ISE. Ein früherer Ausfalltest der ISE zeigt, dass auch hier kein Unterschied darin besteht, welche Cisco ISE der aktive Node ist. Beide Cisco ISE sind hinsichtlich der RADIUS-Einstellungen identisch respektive synchronisiert zum Zeitpunkt der Fehleranalyse.
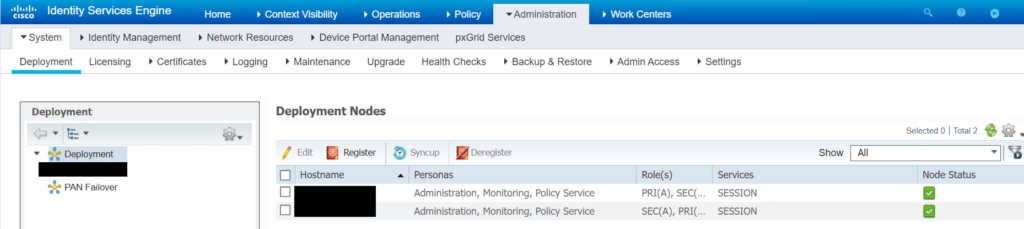
Wir sehen jedoch im Firewall-Log sowie im Live Capture, dass keine RADIUS-Requests von der Cisco ISE zum sekundären Entrust-Server erfolgen. Wir prüfen daher nun die Einstellungen auf der Cisco ISE im Detail. Hier gibt es bereits erste Auffälligkeiten, denn der sekundäre Entrust-Server taucht in keiner der RADIUS-Konfigurationen auf. Wir korrigieren dies und fügen ihn als External RADIUS Server hinzu und nehmen in auch gleich in die RADIUS Server Sequences auf.
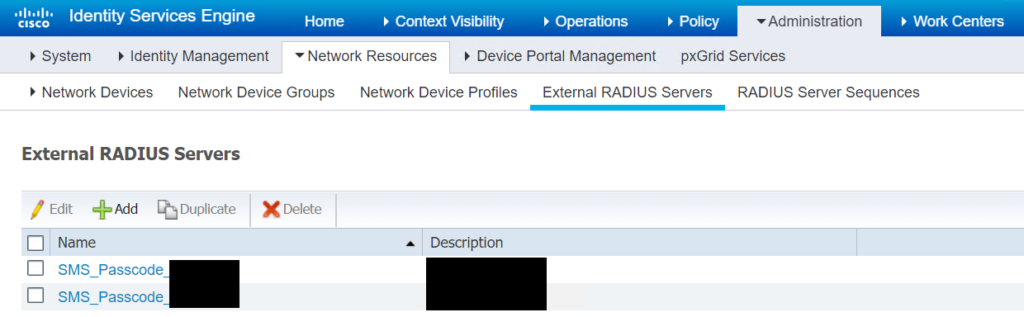
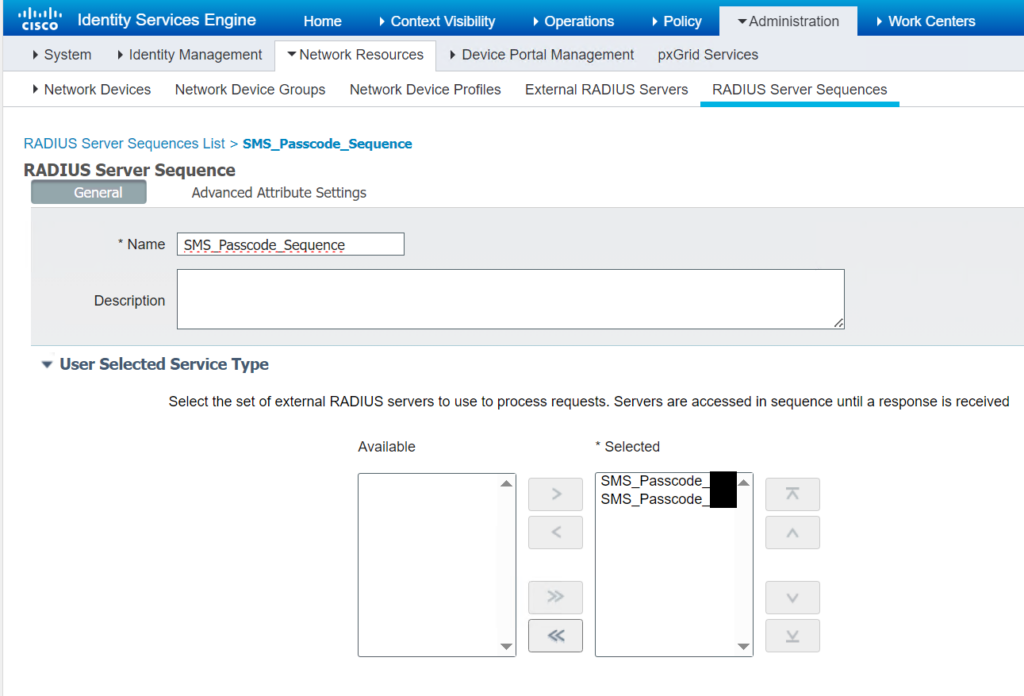
Zuletzt ergänzen wir den sekundären Entrust-Server noch in den External Identity Sources in den RADIUS Tokens als Secondary Server, da hier der primäre Entrust-Server auch hinterlegt ist. An dieser Stelle sei angemerkt, dass die Shared Secrets an beiden Stellen nochmals mit den dokumentierten Werten kontrolliert sind und übereinstimmen.
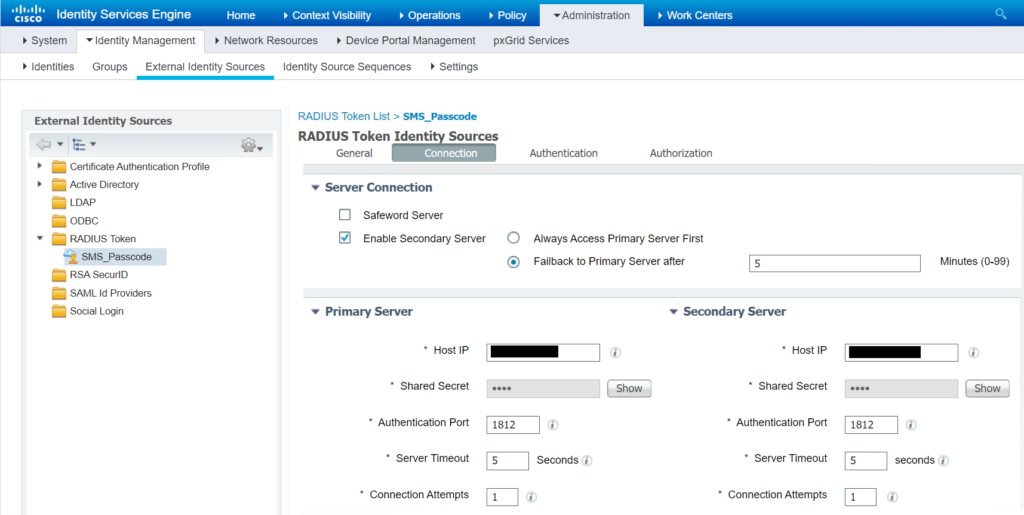
Ab jetzt sehen wir auch Netzwerkverbindungen zum sekundären Server. Diese werden jedoch negativ mit einem Reject von dem Server beantwortet.

Wir gehen daher nun zuletzt auf die beiden Entrust-Server und kontrollieren hier die Konfiguration im Entrust Identity Essentials – Configuration Tool. Hier gleichen wir die Einstellungen ab. Parallel prüfen wir das Windows Event Log, da hier Ereignisse zum Windows NPS-Dienst und Entrust protokolliert werden. Sicherheitshalber prüfen wir auch, ob die beiden Cisco ISE als RADIUS-Clients im Windows NPS hinterlegt sind und die korrekten Shared Secrets verwendet werden. Die NPS-Einstellungen sind jedoch unauffällig.
Wir stellen allerdings fest, dass der zweite Entrust-Server exklusiv den primären Entrust-Server als Authentication backed service host referenziert. Der primäre Entrust-Server verweist ebenfalls exklusiv auf sich selbst. Aus diesem Grund können auch Codes versendet werden, wenn wir der Cisco ISE die Verbindung zum primären Entrust-Server verbieten, aber die Kommunikation zwischen den Entrust-Servern noch zulassen. Wir nehmen daher beide Server in die Konfiguration des jeweils anderen Servers auf und stellen ein, dass jeder der Server sich selbst mit höchster Priorität verwendet.
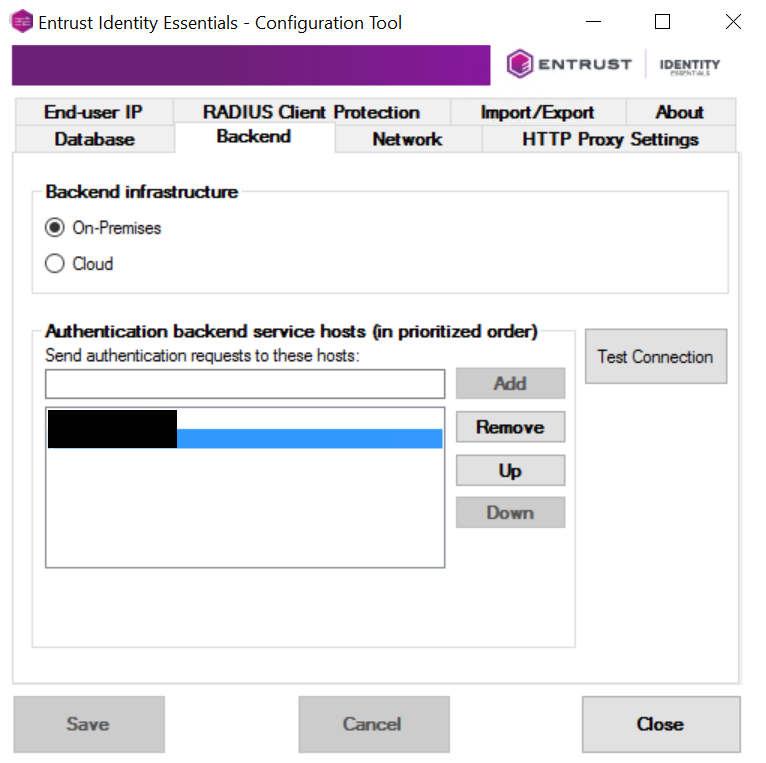
Wir wiederholen nun die Tests in verschiedenen Konstellationen, diese verlaufen nun positiv und der Code wird versendet. Der Ausfalltest kann nun erfolgreich abgeschlossen werden.
Zusammenfassung
Zusammenfassend sind nun folgende Schritte erfolgt:
- FortiGate-Firewalls
- Kontrolle der Firewall-Regeln
- Kontrolle der VPN- und RADIUS-Einstellungen
- Cisco ISE
- Kontrolle des ISE-Cluster-Status
- Kontrolle der RADIUS-Konfiguration
- Anlage des sekundären Entrust-Servers in der ISE an mehreren Stellen
- Kontrolle des Shared Secrets auf Korrektheit
- Entrust-Server
- Kontrolle Windows NPS-Dienst und Shared Secrets auf Korrektheit
- Kontrolle Windows Event Log auf beiden Entrust-Servern
- Kontrolle Entrust-Konfiguration auf beiden Entrust-Servern
- Anlage des sekundären Entrust-Servers im Configuration Tool